AnDE#
- class skbn.AnDE(n_dependence=1, n_bins=5, strategy='quantile', alpha=1.0, n_jobs=None, categorical_features=None, bernoulli_features=None, gaussian_features=None)#
Averaged n-Dependence Estimators (AnDE) [Generative].
This is the standard generative model described by Webb et al. [1]. It aggregates the predictions of sub-models (SPODEs) using an Arithmetic Mean.
\[P(y|x) \propto \sum_{i} P_i(y, x) \equiv \log \sum_{i} \exp(\text{JLL}_i)\]This implementation extends the original AnDE by supporting mixed data types (Gaussian/Categorical) through the Super-Class strategy.
- Parameters:
- n_dependenceint, default=1
The order of dependence. - n=1: AODE (Averaged One-Dependence Estimators). - n=2: A2DE.
- n_binsint, default=5
Bins for discretizing super-parents.
- strategystr, default=’quantile’
Discretization strategy.
- alphafloat, default=1.0
Smoothing parameter.
Methods
fit(X, y)Generative fitting.
Get metadata routing of this object.
get_params([deep])Get parameters for this estimator.
predict(X)predict_log_proba(X)predict_proba(X)score(X, y[, sample_weight])Return accuracy on provided data and labels.
set_params(**params)Set the parameters of this estimator.
set_score_request(*[, sample_weight])Configure whether metadata should be requested to be passed to the
scoremethod.- fit(X, y)#
Generative fitting. Learns the joint probability P(y, x) for each subspace (SPODE) by counting frequencies.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Training vectors.
- yarray-like of shape (n_samples,)
Target values.
- Returns:
- selfobject
Returns the instance itself.
- get_metadata_routing()#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)#
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- score(X, y, sample_weight=None)#
Return accuracy on provided data and labels.
In multi-label classification, this is the subset accuracy which is a harsh metric since you require for each sample that each label set be correctly predicted.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Test samples.
- yarray-like of shape (n_samples,) or (n_samples, n_outputs)
True labels for
X.- sample_weightarray-like of shape (n_samples,), default=None
Sample weights.
- Returns:
- scorefloat
Mean accuracy of
self.predict(X)w.r.t.y.
- set_params(**params)#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') AnDE#
Configure whether metadata should be requested to be passed to the
scoremethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inscore.
- Returns:
- selfobject
The updated object.
Examples using skbn.AnDE#
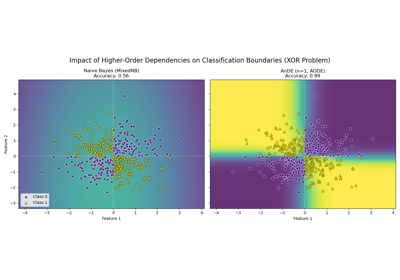
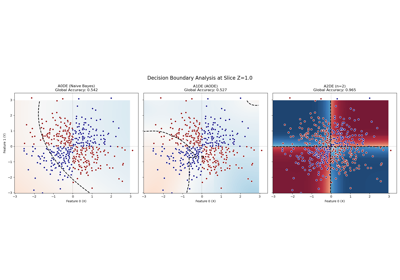
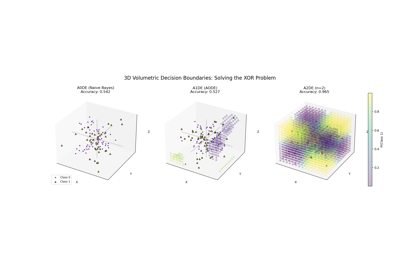
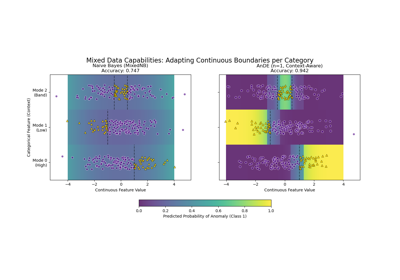
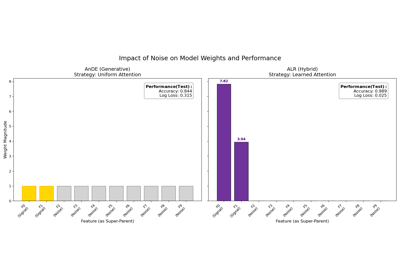
Interpreting ALR: Automatic Feature Selection via Weights
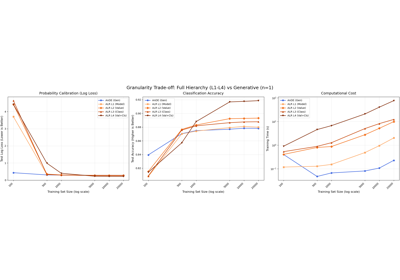
Data Efficiency & Complexity: Generative vs. Hybrid Levels (L1-L4)